
こんにちは!AIサービス開発室の鈴木です。4月に入って、17名の新しい仲間が入社しました。その中にはAIに関心を持って入社してくれた人もいるので、そういう社員の期待にも応えられるようにがんばりたいと思います!!さて、今回は複数ある画像のうち類似するもの同士でクラスタリング(=グループ分け)する方法についてご紹介します。
当社では、AIを用いた画像系のサービスを検討しています。本エントリーで紹介する技術は、例えば、連続撮影した写真からベストショットを抽出するといった用途で使えるのではないかと考えているところです。早速、実験した内容についてお見せしていきましょう。
実験データ
実験データとして、スマホで以下のように12の場面をそれぞれ連写した写真を用いました。各場面それぞれ8~17枚、合計177枚の写真を用意しました。これらの写真をAIが12のクラスタに分けられれば実験は成功です。

実験で用いた技術
クラスタリングに用いた技術を紹介します。私たちは、機械学習のx-meansというクラスタリングのアルゴリズムを使うことにしました。x-meansは、k-meansというアルゴリズムを応用したものです。k-meansではデータを何個のクラスタに分割するかを人間が指定する必要がありましたが、x-meansではアルゴリズムが最適なクラスタ数を決定するためその必要がありません。クラスタの分割数を人間が指定しなくても良い方がアプリへの適用を考えると有用と考えたので、k-meansではなくx-meansを実験対象とした次第です。
ただし、画像データをそのままx-meansに入力しても良い結果はでません。(実際やってみたのですが、人間が納得するようなグループ化には程遠かったです。)なぜなら、画像データは縦の長さ×横の長さ×チャネル(赤・緑・青の3チャネル)というクラスタリングをするには次元(=パラメタ)が多すぎるからです。例えば、今回の実験データであれば次元数は224×224×3=150528となります。人間であれば、画像を一目見てその特徴を把握することが可能ですが、コンピューターは150528ものパラメタを用いて画像の類似度を測る必要があるのです。
そのため、x-meansによるクラスタリングをする前に、ディープラーニングを用いて各実験データの特徴を抽出することによって、データの次元数を削減することにしました。なお、ディープラーニングとはデータの特徴を自動抽出するAIのアルゴリズムの総称です。画像処理をおこなうディープラーニングには種類が多くあります。今回は計算量が少なくて精度もそこそこ高いと言われているMobileNet V3というモデルに対して、Imagenetというデータセットを学習させたものを使うことにしました。これにより各実験データの次元数を1280にまで削減することができます。
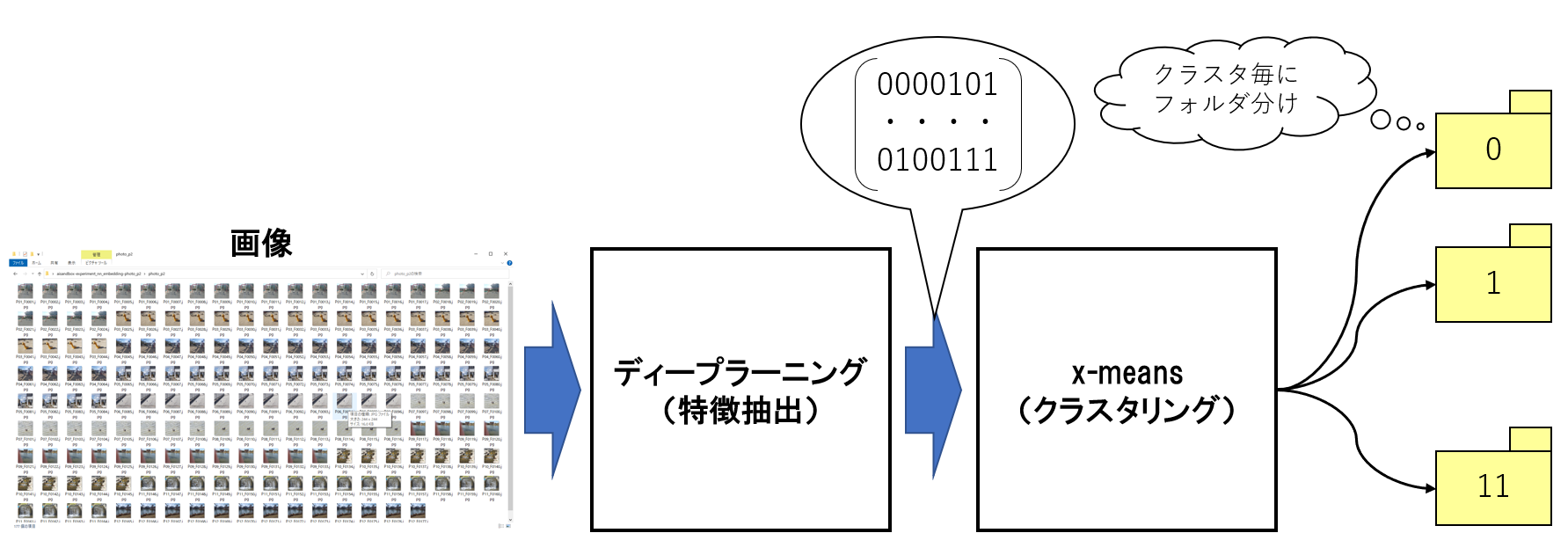
今回の実験で作成したプログラムの処理概要を図にすると以下のようになります。ディープラーニングによって各画像の特徴を表すテンソル(=数値の集まり)を求めて、そのテンソルをインプットにしてx-meansによるクラスタリングをおこないました。そして、クラスタリングした結果の画像は、クラスタ毎に0から始まる連番のフォルダに保存するようにしました。
実験結果
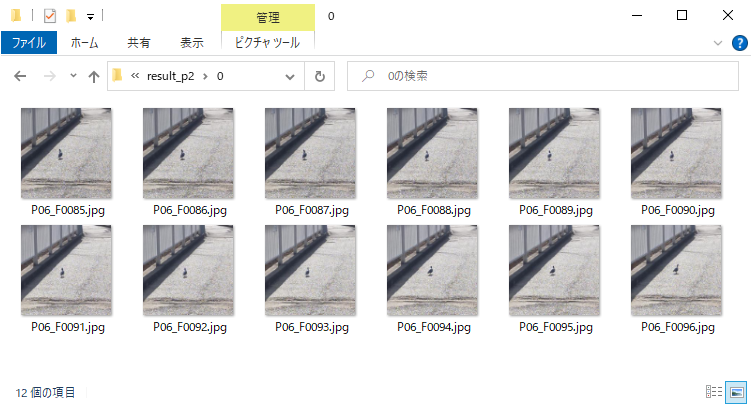
12種類あった場面をx-meansによって13種類にクラスタリングすることができました。1種類多くなっているのは先にお示しした実験データの一番左上のブランコの画像17枚を、本来は一つのクラスタにしてほしいところを、二つのクラスタに分けてしまったためです。それ以外は、余計にクラスタを分けることはありませんでしたし、一つのクラスタに他の場面が混じることもありませんでしたので、概ね上手くいったと言ってよいでしょう。
以下はグループ分け後のフォルダです。同一の場面のみをグループ分けしてフォルダに格納することができました。
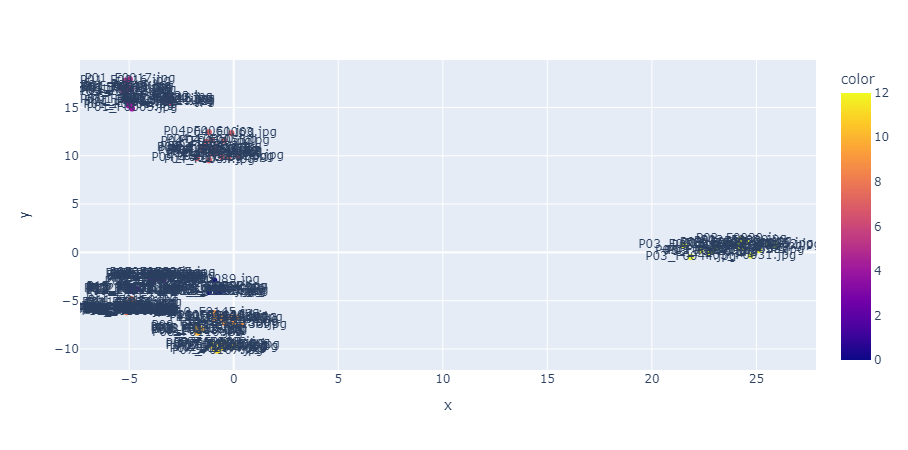
ちなみに、1280次元だと人間は直感的に類似性を判定できませんが、PCAという機械学習アルゴリズムを用いてさらに次元削減をして2次元にまで次元削減した結果を散布図にプロットした結果が以下になります。ファイル名をプロットしているため少し見づらいですが、こうして見るといくつかのクラスタに分けられそうな感じがします。ディープラーニングによる特徴抽出がいかに有効か視覚的にわかっていただけるのではないでしょうか。
まとめ
今回のエントリーでは、x-meansを用いて類似画像をクラスタリングする方法について実験しました。その際に、画像をそのままx-meansの入力にするのではなく、ディープラーニングで特徴抽出したテンソルを入力にすることで精度の高い結果が得られることがわかりました。特徴抽出に用いたMobileNetV3は、元々、何を表す画像かを判定するという画像分類用のモデルです。しかし、今回のように本来の目的とは違う形で、単なる特徴量抽出器として流用できることがわかりました。モデルを一から作って、大量のデータで学習させなくても、既存のモデルを流用することで、目的を果たせるケースがあることを身をもって知れたのは大きな収穫でした。