
こんにちは!AIサービス開発室の鈴木生雄です。最近、Webニュースで若宮正子さんの存在を知りました。気になって検索してみると首相官邸のWebページにも掲載されるくらい有名な方だということがわかりました。80代でプログラマーをやっているって本当にすごい!エンジニアの一つのロールモデルになる方だと思います。また、同じようにお年を召されてもエンジニアとして活動されている方には、楽天の技術理事を定年退職後に東京大学の博士課程に進まれた吉岡 弘隆さんがいます。私は、Developers Summit2019で彼のセッションを聴講した時に、いくつになっても現役という感じがする素敵な方だなと思いました。年齢が下の人の活躍も刺激になりますが、上の人の活躍は自分が同じ年齢になった時のことを考えるきっかけになるので、また違った意味で刺激になりますね。参考にしながら益々励んでいきたいと思います。
さて、本日は「顔検出AIモデルの精度向上」というテーマです。以前に顔認証AIの学習用データの元になる顔写真を集めるというエントリーで、当社の社員から学習用のスナップ写真を集めるという取組について紹介しました。今回はその取組で集まった写真を用いて、実際に顔検出AIの学習を行った経過および結果について報告します。
集まった写真の数
今回、社員へのスナップ写真の提供をお願いしたところ、30,555枚の写真を集めることができました。元々持っていた5,203枚の写真と合わせると35,758枚となりました。
学習データの作成方法
集まった写真を学習用データにするためにアノテーション(=どこに顔があるかをマークする作業)をおこなう必要があります。ただし、一枚一枚の写真に対して手作業でアノテーションをしていては大変な労力がかかってしまいます。そこで、私たちは以下のようにInsightFaceという既存のAIモデルに推論させることで、アノテーションを自動化することにしました。

これで労力をかけずにアノテーションできると思いましたが…
問題発生
そんなに物事は思い通りには進みませんでした。自動でおこなったアノテーションの結果を見てみると、以下のように「検出漏れ」や「検出誤り」がたくさんあることに気が付いたのです。
検出漏れの例

赤い丸で囲った部分が検出漏れなのですが、結構な数が漏れていますよね。
検出誤りの例

検出誤りも散見されました。上記のうち左の画像では耳が顔と判定されていますし、右の画像では水槽に移りこんだ顔が検出されています。後者については正しく検出したとみなしてもよいケースはあるかもしれませんが、今回は作成しようとしているアプリの要件から言って誤検出とみなすことにしました。
漏れ・誤りへの対応策
漏れや誤りを含むデータによる学習すると、間違った方向に学習をしてしまうため、AIモデルの精度向上は期待できません。なぜなら、ディープラーニングの本質は合成関数の重み調整にあるからです。そのため、今回は自動的にアノテーションしたデータに対して、人の目で見て採否を仕分けをすることで学習データの品質を高めることにしました。その際、人の目でアノテーションがみられるように当社エンジニアにツールを以下のような作ってもらいました。
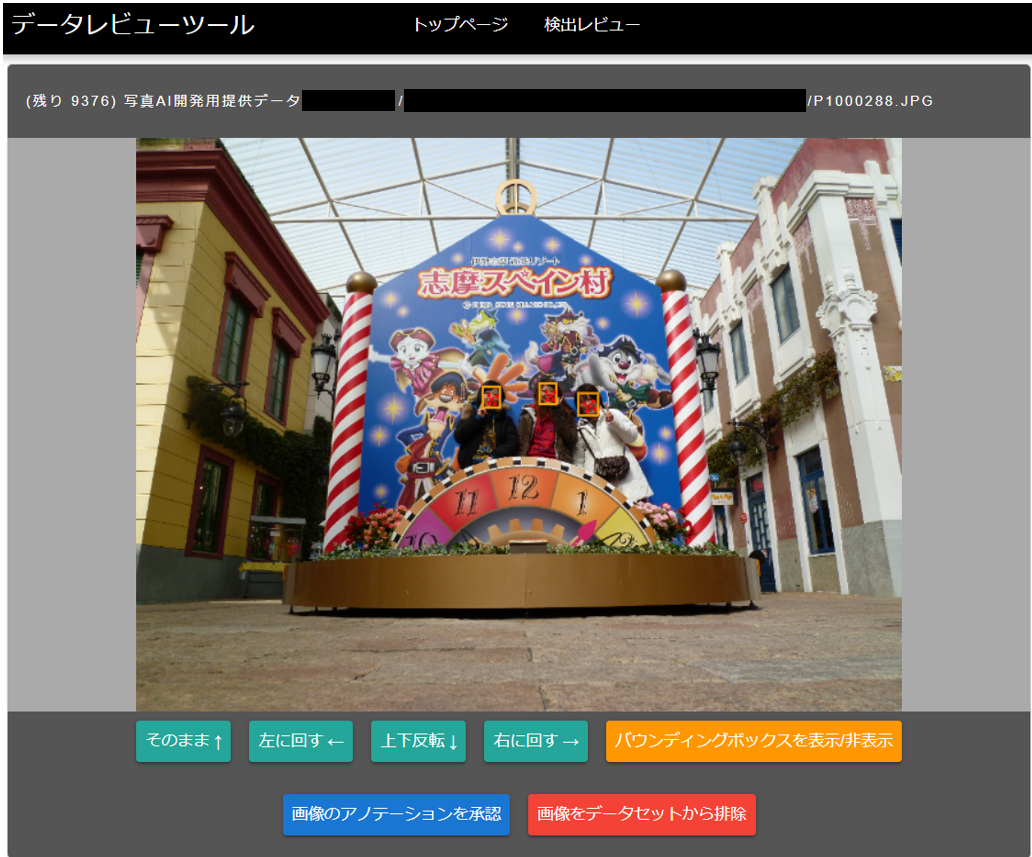
ツールの使い方はいたってシンプルです。順送りで表示されるスナップ写真に対して「画像のアノテーションを承認」または「画僧をデータセットから削除」のいずれかを押すだけで、学習用データとしての採否を仕分けられます。このツールを用いて、35,758枚のデータのうち20,000枚を仕分けしました。けっこうシビアな目で判定したので、20,000枚のうち学習データとして採用したものは5,000枚に留まりました。
結果
さて、仕分けを行ったデータで学習した結果はいかに!ということで、仕分け前と後それぞれについての学習結果を以下に示します。APS(Average Precision Score)は、顔検出AIモデルの性能を評価するための指標の一つで、高い方が性能が良いことを表します。

仕分け前と後でAPSこそ+0.07しか変わっていませんが、サンプルの推論結果をみると仕分け後の方が多くの顔を検出できるようになったことがわかります。これらのことから、人系によるアノテーションのレビュー(=採否の仕分け)を行うことでAIモデルの性能が向上したと言えそうです。
課題
今回は人系によるアノテーションのレビューをおこない学習データの品質を高めることで顔検出AIモデルの精度向上を果たすことができました。ただし、その一方で二つの課題が浮き彫りになりました。
課題1:人手によるアノテーションに係る工数
今回は20,000枚のデータの採否を決めるだけの作業でしたが、それだけでも30人時程度の工数がかかりました。そして、レビューの結果4分の3に当たる15,000枚を捨てています。(なんてもったいない!)その中には、アノテーションを修正すれば使えるものもありそうでしたが、修正に工数がかかるため諦めました。もしこれらの捨てているデータを修正して活かすようにするのであれば、さらに膨大な時間が必要になることでしょう。この課題に対応するためには、巷にあるあのアノテーションツールを検証したり、場合によっては自作したりして、効率の良いアノテーション手法を確立する必要があると考えています。
課題2:担当者による品質のバラつき
今回は二人で手分けしてレビューを行ったのですが、担当者によって採否の判定基準が異なるという問題もありました。例えば、顔の大きさ、顔の角度、アクセサリ等による遮蔽状況、明るさ、写り(ブレ・ピント)等の条件が違ったときに判断を厳密に合わせることができませんでした。この課題に対応するためには誰がアノテーションをしても品質が均一になるような明確な基準を作成する必要があると考えています。
今後の予定
顔検出のAIモデルの精度向上をやってみて大変さがとてもよくわかりました。写真を収集するだけでもそれなりに大変でしたが、その上で前出のような課題に対応しながら、品質のよいアノテーションを施すことを考えるとすると、それなりに大きな工数が必要になることは間違いありません。そのため私たちは、現時点において、自前のAIモデルを組み込む形ではアプリ開発することを棚上げすることにしました。代わりに他社製の顔分析用のAPIを組み込むことでサービスのリリースまでのスピードアップを図ります。本ブログにおいても、今後しばらくはAIのモデル開発からは離れて、自社サービス開発に関するエントリーを投稿していこうと思います。
いずれにしても、ありのままを面白く伝えられるように書いていきたいと思いますので、ぜひご期待ください。