
こんにちは!AIサービス開発室の鈴木生雄です。8月、夏本番、毎日暑いですね~。私はできるだけ、室内で昼は活動して、外出は夜に限るというふうにして熱中症にならないように気を付けています。みなさんも体調を崩さないようにお気をつけください。さて、今回のブログのネタですが、開発フェーズに入ったことにより、現時点では自社サービスについてお伝えすることがないため、私が実験的に作ったQ&A Chatbotについてお届けしたいと思います。ぜひ、気軽に読んでください。
以前にこのブログで、ChatGPTの Chat Completion APIを用いてLINEのChatbotを作ってみた感想 というエントリーを投稿しました。このように、ChatGPT API を用いれば簡単にChatbotを作成することができます。これはこれで、ただ遊ぶ分には面白いですが、実用的とは言えません。その理由として、ChatGPTが過去の情報(2021年9月時点)に基づいて文章を生成していることと、ニッチなドメインの情報を保持していないことが大きいと思います。ChatGPTが外部の情報とリンクすることができればより役に立つモノが作れると思いますし、実際、OpanAIはChatGPT Pluginsという形でそれを実現し始めています。個人的には今後、ベースのモデルの改良と外部情報とのリンクの両方が並行して進展していくのではないかと思っています。
さて今回、そうしたトレンドを踏まえて、LlamaIndexというフレームワークを用いて、ChatGPTに外部情報を連携させた上で文章を生成させるという実験をやってみましたので、その過程と結果についてお伝えしていきます。
LlamaIndexとは
LlamaIndexとは、入力プロンプトにコンテキストを埋め込むというアプローチで、外部情報をChatGPT等の大規模言語モデル(LLM)に接続することによって、Q&Aを実現するフレームワークです。
LlamaIndexが最終的にやってくれることは、以下のようなプロンプトをChatGPTに送って回答を得ることです。なお、ここで言う{コンテキスト情報}はChatGPTに与える外部情報、{質問文}は利用者からの質問に当たります。
以下にコンテキスト情報を提供します。
---------------------
{コンテキスト情報}
---------------------
この情報を踏まえて、次の質問に答えてください。{質問文}
最終的にやることがシンプルなので、いかにして外部情報を検索可能な状態で保持するか、いかにして質問文から関連する外部情報をコンテキスト情報として抽出するかが課題になります。LlamaIndexでは「インデックス作成」と「質問回答作成」を次の手続きで行うことによって、前出の課題に対応しています。
インデックス作成
- データを読み込み、細かいチャンクに分割する。
- 分割したチャンクごとにOpenAI Embeddings APIを用いて、各文章のVectorデータを取得する。
- Vectorデータを格納したインデックスファイル(JSON形式)を作成する。
(インデックスファイルは、チャンク毎にノードという単位で構成される。)
質問回答
- 質問のVectorデータをOpenAI Embeddings APIを用いて取得する。
- インデックスファイル内の各ノードを検索し、関連性の高いノードを抽出する。
- 抽出したノード内のテキストを参照しながら、OpenAI ChatGPT APIへ問い合わせをする。
- OpenAI ChatGPT APIからの返信をもとに、最終的な返信を作成する。
作ったもの
本ブログの過去エントリーについてのQ&AをおこなうChatbotを作成しました。ちなみに、普段使いしやすいという理由で、過去に作ったドラえもんGPTと同じく、チャット用の画面はLINEを用いました。
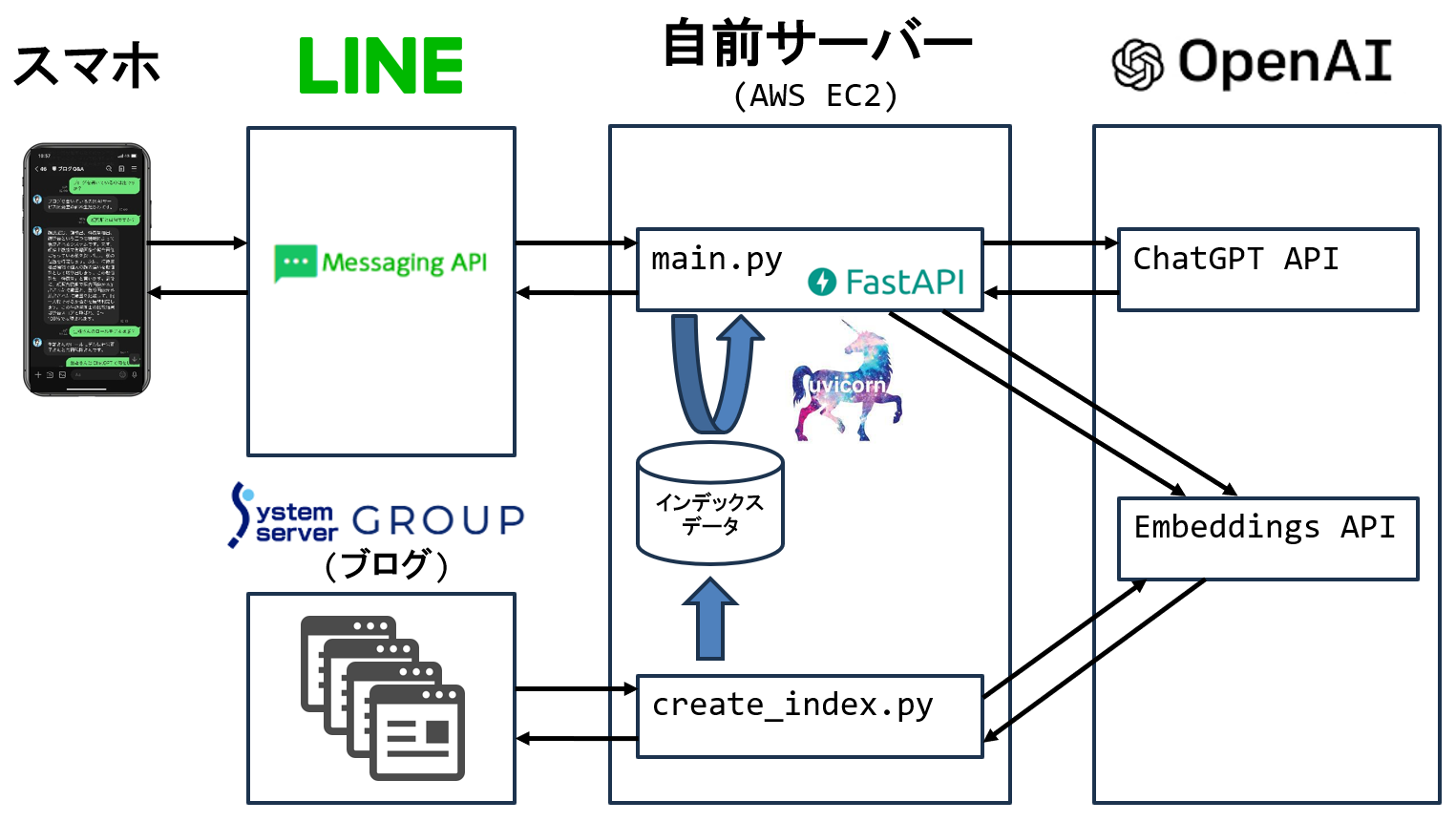
システム構成は以下のとおりです。個々の説明は割愛しますが、本エントリーの「LlamaIndexとは」のセクションと照らしてみてもらえると流れを追えると思います。下図のcreate_index.pyがインデックス作成、main.pyが質問回答を担っています。蛇足になりますが、自前サーバーにはAWSのEC2を用いました。LINEのMessagingAPIを使うためにドメイン登録やTLS化が必要だったのですが1時間程度で難なく完了しました。この手の実験をするのに、もはやクラウドは欠かせないですね。
言語はpython3.9.10です。主要なライブラリのバージョンは以下のとおりです。pipでこれらをインストールすると依存関係にあるライブラリは自動でインストールされます。
fastapi==0.101.0
line-bot-sdk==3.0.3
llama-index==0.7.19
openai==0.27.8
uvicorn==0.23.2
一つはまりポイントとなったのは、line-bot-sdkとllama-indexの両方ともがpydanticというライブラリに依存しているのですが、line-bot-sdkの最新バージョン(当時3.2.0)がpydantic 2.x系を求めるのに対して、llama-indexの最新バージョン(当時0.7.19)はpydantic 1.x系を求めるため、コンフリクトが発生する点です。そのため、今回はline-bot-sdkのバージョンを3.0.3に下げることによって、同じpydantic 1.x系で動作するようにしました。
参考までに、ソースコードも貼っておきます。
create_index.py
import logging
import sys
import openai
from llama_index import SimpleWebPageReader
from llama_index import VectorStoreIndex
from llama_index import ServiceContext
from llama_index import set_global_service_context
from llama_index.llms import OpenAI
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
# Llamaindexの設定
openai.api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(model="gpt-4", temperature=0, max_tokens=2048)
service_context = ServiceContext.from_defaults(llm=llm)
set_global_service_context(service_context)
# 指定したURLのブログを読み取る。
documents = SimpleWebPageReader(html_to_text=True).load_data(
[
"https://www.system-server.com/wp/blog/574/",
"https://www.system-server.com/wp/blog/549/",
"https://www.system-server.com/wp/blog/544/",
"https://www.system-server.com/wp/blog/535/",
"https://www.system-server.com/wp/blog/530/",
"https://www.system-server.com/wp/blog/527/",
"https://www.system-server.com/wp/blog/518/",
"https://www.system-server.com/wp/blog/505/",
"https://www.system-server.com/wp/blog/498/",
"https://www.system-server.com/wp/blog/484/",
"https://www.system-server.com/wp/blog/477/",
"https://www.system-server.com/wp/blog/467/",
"https://www.system-server.com/wp/blog/448/",
"https://www.system-server.com/wp/blog/441/",
"https://www.system-server.com/wp/blog/400/",
]
)
# インデックスの作成・保存
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir="./storage")main.py
import logging
import sys
import os
from fastapi import FastAPI, Request, HTTPException
from linebot import WebhookParser
from linebot.v3.messaging import (
AsyncApiClient,
AsyncMessagingApi,
Configuration,
ReplyMessageRequest,
TextMessage,
)
from linebot.v3.exceptions import InvalidSignatureError
import openai
from llama_index import StorageContext
from llama_index import load_index_from_storage
from llama_index import ServiceContext
from llama_index import set_global_service_context
from llama_index.llms import OpenAI
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.INFO, force=True)
# LINEの設定
channel_secret = os.getenv("LINE_CHANNEL_SECRET", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
channel_access_token = os.getenv(
"LINE_CHANNEL_ACCESS_TOKEN",
"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
)
configuration = Configuration(access_token=channel_access_token)
app = FastAPI()
async_api_client = AsyncApiClient(configuration)
line_bot_api = AsyncMessagingApi(async_api_client)
parser = WebhookParser(channel_secret)
# Llamaindexの設定
openai.api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(model="gpt-4", temperature=0, max_tokens=2048)
service_context = ServiceContext.from_defaults(llm=llm)
set_global_service_context(service_context)
# インデックスの読み込み
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
@app.post("/")
async def handle_callback(request: Request):
"""LINEからリクエストがあった際にブログに関する質問として受け取って応答します。"""
signature = request.headers["X-Line-Signature"]
body = await request.body()
body = body.decode()
logging.debug(body)
try:
events = parser.parse(body, signature)
except InvalidSignatureError:
raise HTTPException(status_code=400, detail="Invalid signature")
for event in events:
logging.debug(type(event))
line_msg = event.message.text
logging.debug(line_msg)
# Llamaindex経由でChatGPTに回答結果を作らせる。
result = query_engine.query(line_msg)
await line_bot_api.reply_message(
ReplyMessageRequest(
reply_token=event.reply_token,
messages=[TextMessage(text=str(result))],
)
)
return "OK"
所感
大規模言語モデル(LLM)が最新の情報やニッチな情報を扱えるようにするための、今回紹介したものと異なるアプローチには、ファインチューニングがあります。しかし、以前に自前でモデル学習をやってみた経験則から言うと、現段階においては、エンドユーザーや業務アプリの開発者がファインチューニングは行うのはハードルがとても高いと思います。そのため、私としてはChatGPT等のベースのLLMを中心にして、LlamaIndex や ChatGPT Plugins のように、入力プロンプトにコンテキスト情報を与えるというアプローチのフレームワークやツールが次々と登場して、エコシステムを形成していくのではないかと予想しています。
それから、LlamaIndex を用いたアプリ開発については、今回の実験でQ&A Chatbotが簡単に作れることは分かりましたが、本当に実用的なものが作れるとはまだ言い切れないと思っています。私自身Webサイト等にあるAIコンシェルジュとかAIヘルプデスクを使って役に立ったという経験がないため、この点においてどうしても懐疑的になってしまうところもあります。ですから次は、採用Q&Aや自社アプリQ&Aのように実用を前提にしたテーマで検証を行ってみたいと思っています。