
こんにちは!AIサービス開発室の鈴木生雄です。いきなりですが、最近知った豆知識を披露させてください。音楽や音声関連のサービスでは.fmというドメインがよく用いられていますよね。例えば、last.fm(音楽の再生履歴を記録・共有するサービス)とかlisten.fm(ネットラジオ)とか。これは「fm」という文字を見て、「FMラジオ」や「音楽」を連想する人が多いからなんだそうです。しかし、この.fmというドメイン、実はミクロネシア連邦に割り当てられている国別コードトップレベルドメイン (ccTLD)だって知っていましたか?つまり、もともとは「Federated States of Micronesia(ミクロネシア連邦)」という国を表すドメインなのです。(日本で言えば.jpですね。)なお、Wikipedia(.fm)によると、
.com.fm、.net.fm、.org.fmなどの予約されたものを除いては、誰でも.fmドメインに属するセカンドレベルドメインの取得が可能である。取得の際に支払われる登録料の一部は、ミクロネシア連邦の収入となる。
ということらしいです。どの程度の収入になっているかは調べられませんでしたが、国名が金を稼ぐなんて面白いと思いました。ちなみに、ツバルという国のccTLDは.tvなんですが、こちらは映像サービスでよく用いられているようです。
さて、今回は「AIプログラミングに挑戦」シリーズということで、AIによる音声合成でPodcastを配信をやってみたということについてお届けします。
やったこと
- テキスト音声変換(いわゆるText to Speech)
前回に確立した方法で作成したPodcastのプロットのテキストをVOICEPEAKで音声ファイルに変換した。 - Podcast配信
音声ファイルをPodcastの配信プラットフォームSpotify for Creatorsをアップロードして配信した。
の二つです。
テキスト音声変換
テキスト音声変換の製品やサービスはいろいろありますが、今回はVOICEPEAKを使いました。なぜなら、過去に自社のeラーニングコンテンツを作成する際に使ったことがあったので使い慣れているからです。他にはにじボイスも使い勝手がよさそうな感じがしましたが、サブスクの料金がかかるのがネックになるので止めました。
テキスト音声変換サービスをいろいろと調べていたら、ちょうど昨日3/20にOpenAIからgpt-4o-mini-ttsという新しい音声読み上げモデルがリリースされました。
Introducing next-generation audio models in the API (OpenAI; March 20, 2025)
https://openai.com/index/introducing-our-next-generation-audio-models/
gpt-4o-mini-ttsについて特筆すべきは、このモデルが複数の話し方(speaking styles)をサポートしており、ユーザーはAPIを通じて「共感的に」「プロフェッショナルに」といった具体的なトーンの指定が可能な点です。たとえば、カスタマーサポートボットに「優しく落ち着いた口調で話す」よう指示すれば、状況に応じた最適な音声出力が可能になります。
ちなみに、gpt-4o-mini-ttsは OpenAI.fm というデモサイト(下図はその画面イメージ)で簡単に試せますので、興味ある方はやってみてください。
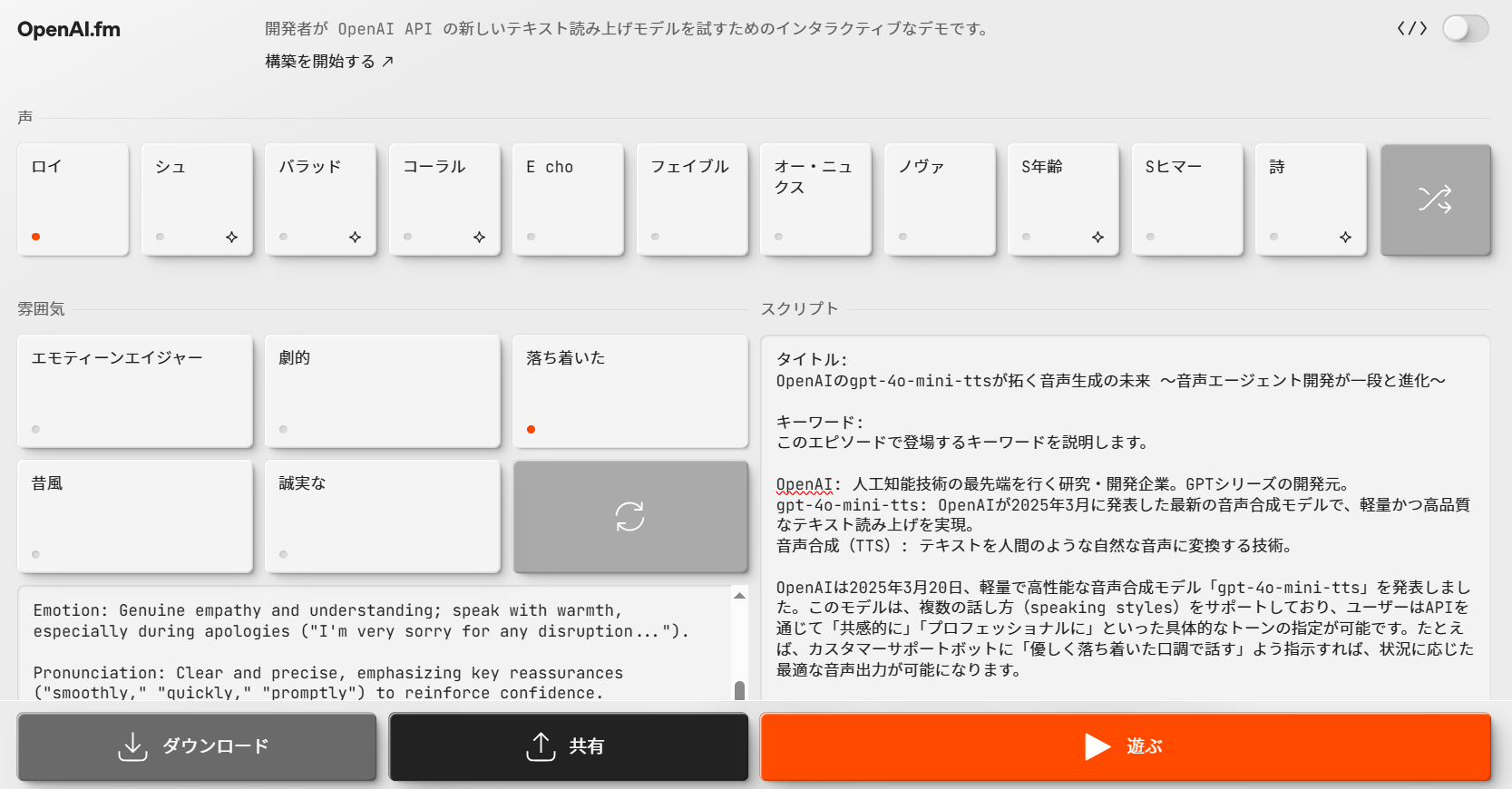
また、料金については料金表に gpt-4o-mini-tts: ~1.5 cents / minuteとあったので、私のユースケースくらいだったら安価に実現できそうな感触を持ちました。
Podcast配信
Podcastの配信プラットフォームは、Spotify、Apple Podcast、Youtube Music、Amazon Music が候補として挙がりました。それぞれに調べていると、Spotifyは、設定すればRSSフィードによって、Apple PodcastとAmazon Musicに同時配信できることがわかったので、Spotifyにしました。(ちなみに蛇足ですが、RSSフィードってあまり聞かなくなった印象がありましたが、Podcast配信では相変わらず活用され続けているのですね。フィードリーダーを使ってブログを読んでいた時代が懐かしく思い出されました。)
以下の埋め込みURLで聴けますので、ぜひ聴いてみてください。
初回である今回は6本のエピソードを配信しました。そのうちの「OpenAIのgpt-4o-mini-ttsが拓く音声生成の未来 〜音声エージェント開発が一段と進化〜」というタイトルのエピソードだけはgpt-4o-mini-ttsを用いて音声を作成しています。(残り5本はVOICEPEAKです。)なお、gpt-4o-mini-ttsの方はデモ環境のOpenAI.fmを使っていることにより文字数に制限があったので、コンテンツとしては短くなってしまっています。
まとめ
今回は事前に用意したテキストを基に、テキスト音声変換をおこなってそれをPodcastで配信したことについてざっくりとお伝えしました。ソフトやサービスの使い方を覚えるのが多少手間ですが、ある程度ITを使っている人であれば、ここまでに1日2日あれば十分に到達できるのではないかと思いました。今後はコンテンツの質を高めることと、より労力を減らして継続しやすくすることの二つを重点に置いて、以下をバックログとして取り組んでいきたいと思います。
- プロンプトのブラッシュアップ
- Apple PodcastとAmazon Musicへの同時配信設定
- AIによるBGMやジングルの作成
- 自動化プログラムの作成