
こんにちは!AIサービス開発室の鈴木生雄です。3月30日にふくい桜マラソン2025 に参加してきました。その日は最高気温8.7℃という肌寒い日だったのですが、マラソンを走るにはちょうどよく、とても気持ちよく走れました。おかげでタイムは3時間23分17秒と、プライベートベストを約6分更新することができました。今年で43歳になりますが、まだまだベストを更新し続けられるようにがんばります。
さて、今回は「AIプログラミングに挑戦」シリーズの第4弾をお届けします。前回はプロット作成をMyGPT、音声ファイル作成をVOICEPEAKでおこなってPodcastを公開しました。今回はプロット作成から音声ファイル作成までを一度におこなうプログラムについて、再現可能なレベルで詳細に説明していきます。ただし、ChatGPTのPlusまたはProユーザーであって、APIキーの作成が完了していることが前提になる点はご了承ください。
やったこと
やったことはプロットを作成するAssistants(≒MyGPT)の作成とプログラムの作成です。
Assistantsの作成
自動化のプログラムを作成する段階になって調査をしたところ、MyGPT(GPTs)はWeb UI用なので、MyGPTを直接API経由で使うことはできないことがわかりました。代わりにAPI経由で呼び出せるAssistantsというMyGPT相当のものを作ればよいとのことでしたので、開発者用のサイト( https://platform.openai.com/assistants )で以下のようにして作成しました。
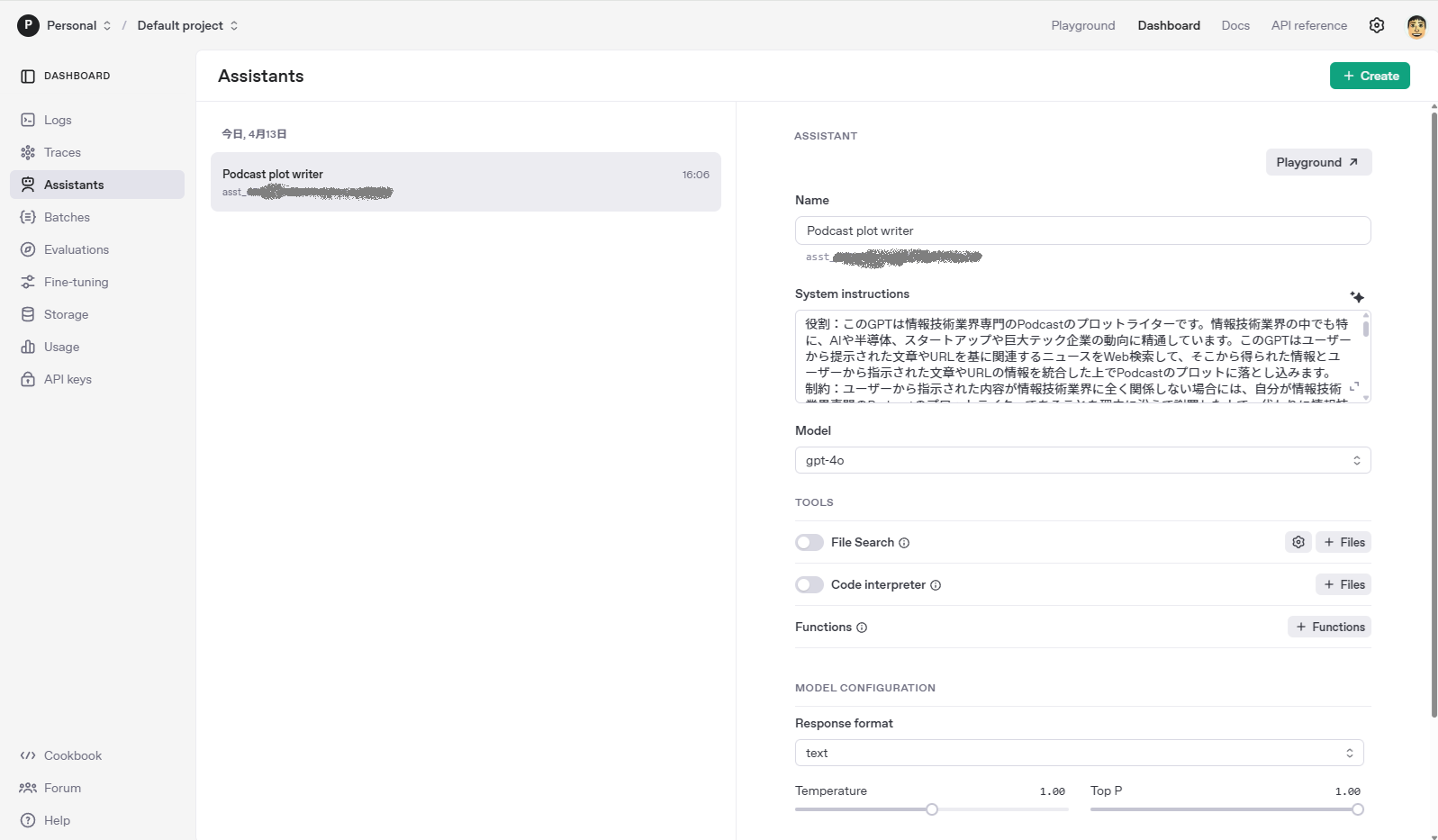
プログラムの作成
今回はSDKが充実しているのと、多少なりとも知っているという理由で言語はPythonにしました。
まず、必要なライブラリをpipでインストールします。
pip install openai openai-agents python-dotenv
ちなみに、dotenvはAPIキーを環境変数として扱うために導入しましたが必須ではありません。.envファイルを作成して、以下のようにAPIキーを書いておきます。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxximport os
from datetime import datetime
from dotenv import load_dotenv
from openai import OpenAI
# ====== 設定 ======
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
ASSISTANT_ID = "asst_xxxxxxxxxxxxxxxxxxxxxxxx"
OUTPUT_FILE = "podcast" + datetime.now().strftime("%Y-%m-%d %H%M%S") + ".mp3"
client = OpenAI(api_key=OPENAI_API_KEY)
# ====== Assistantからプロット生成 ======
def generate_plot(news_input: str) -> str:
thread = client.beta.threads.create()
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=f"このニュースをもとに、ポッドキャストのプロットを作ってください:\n{news_input}",
)
run = client.beta.threads.runs.create_and_poll(
assistant_id=ASSISTANT_ID, thread_id=thread.id
)
messages = client.beta.threads.messages.list(thread_id=thread.id)
return messages.data[0].content[0].text.value
# ====== テキストを音声化して保存 ======
def text_to_speech(text: str, output_path: str = OUTPUT_FILE):
response = client.audio.speech.create(
model="gpt-4o-mini-tts", voice="nova", input=text
)
response.stream_to_file(output_path)
print(f"[完了] 音声ファイルを保存しました: {output_path}")
# ====== メイン処理 ======
def main():
print("ポッドキャスト化したいニュースのURLまたは本文を入力してください(Enterで確定):")
news_input = input("> ").strip()
if not news_input:
print("入力が空です。終了します。")
return
print("[1] プロット生成中...")
plot = generate_plot(news_input)
print(f"[プロット]\n{plot}\n")
print("[2] 音声変換中...")
text_to_speech(plot)
print("[完了] 全処理が完了しました。")
if __name__ == "__main__":
main()
プログラムで作成した音声ファイル
そして、このプログラムで作成した音声がこちらになります。
- 入力
OpenAIは2025年4月11日、ChatGPTの記憶機能を大幅に強化したことを発表しました。これにより、過去のチャット履歴を活用して、よりパーソナライズされた応 答が可能となります。この機能は、EEA(欧州経済領域)および英国を除く、すべてのPlusおよびProユーザーに順次展開されます。※ 上の例ではテキストを入力していますが、ニュースのURLでもOKです。2025/4/16時点ではAssistant APIはWebブラウジング機能を提供していないようです。
- 出力
聴いてみてどうでしょうか?私としてはスピーチの質は完ぺきとまでは言いませんが、伝えたいことが伝わるレベルには達していると言えると思います。VOICEPEAKも優秀なのですが、手動でテキストを入力したり、発音の間違いを直すのが手間だったのでそれらをやらなくて済むのであればとても助かります。今後、いくつかのエピソードで試してみて、問題なさそうならば今回の方法に切り替えたいと思います。
おわりに
今回、ChatGPTのAssistantsとText-to-Speechを利用してPodcastの音声ファイルをプログラムで作成することに成功しました。この経験を通じて、プログラムを介してLLM内の機能を連携させたり、他のLLMやシステムと連携させたりすることで、今まで以上に役立つアプリを作成できるということを実感できるようになりました。
本エントリーでは紹介しませんでしたが、最近、ビッグテック各社やオープンソースコミュニティーでは、外部リソースを使ったり(MCP)、AIエージェント同士が連携したり(A2A)、LLMをワークフローに組み込めるようにしたり(Dify等)、と高度なAIアプリを開発するための仕組みを次々と発表しています。こうした仕組みを活用したAIを組み込んだアプリ開発の時代が迫っていることをひしひしと感じるので、当社としても遅れをとらないようにしていきたいです。